A Faceted query allows you to specify groups/categories in which results will be matched and collected.
Overview
In a GROUP BY aggregation, results are grouped based on the value of a field within each result. In contrast the "Faceted" aggregation allows the user to provide the name and criteria for each group known as a "facet".
Note: a single result can be collected into more than one group, where as a GROUP BY is guaranteed to collect each result into only one of the possible groups (values) for that field (except in the case of multi-select fields such as Components, Fixed/Affected versions etc.)
Facets should be familiar to anyone who has shopped online, where you will often see items divided in arbitrary groups which make it easer to find what you are looking for, i.e.
- $10 and less
- $10 to $50
- $50 or more
- On Special
Being able to break information down into meaningful ranges is a powerfull tool which allows test managers to easily get an overview of the status of testing, and the quality/makeup of their test artifacts.
Examples
If you have a set of data with three distinct statuses:
- Draft
- Approved
- Out Of Date
You could get a count of each type by using this GROUP BY query:
GROUP BY Status { COUNT }
But, what if you just want two counts, one for approved, and the other for both "Draft" and "Out of Date"?
This is where Faceted queries come in handy:
FACETED Equal(Status,Approved) as "Approved",
OrArgs(Equal(Status,Draft), Equal(Status,'Out Of Date')) AS "Not Approved"
{
COUNT
}
In the above query we are creating two "Facets" - the first facet for all matches where the Status is "Approved", and the second which matches any status which is "Draft" or "Out Of Date", and for each we calculate the count.
In the above example, we could also simplify it by counting everything that didn't match the first facets predicate to be counted as the second facet, by using the Unmatched() function:
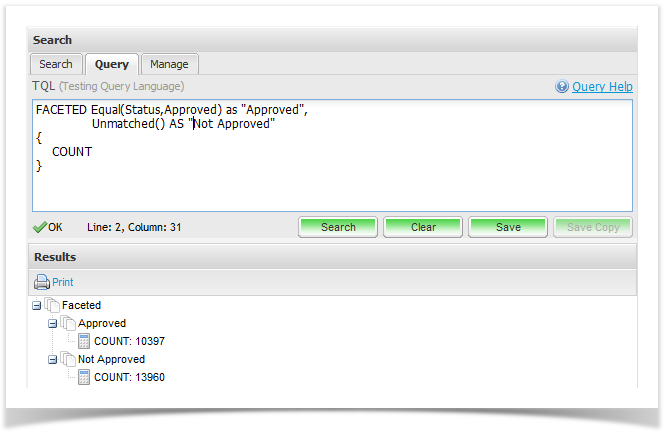
FACETED Equal(Status,Approved) as "Approved",
Unmatched() AS "Not Approved"
{
COUNT
}
In the above example we are only showing two facets - but the number of facets you can define is unlimited - each facet just needs to be seperated by a comma - and at the end of the list of facets you must be define a set of aggregate functions to be executed for each facet, just as you would when writing a GROUP BY query.
Here is an example of the output you would expect from the above example:
Syntax
Faceted aggregations use the following syntax:
FACETED [Facet1],[Facet2],[FacetN] { Aggregation1, Aggregation2.. AggregationN }
Each Facet is a function call with an optional alias (which must be provided in quotes):
<Function Call> [AS "Alias"|AS 'Alias']
If you do not supply an alias, the function call itself followed by the word "Facet" will be used as the name of this facet.
Functions
For a list of supported functions within a Facet, see the Facet Functions topic.