Aggregation
Aggregation queries allow you to take a normal TQL query and calculate summary information over the set of results. It is a powerful feature that provides the functionality within Enterprise Tester to support complex reports and graphs, and we put that power into your hands.
Introduction
Aggregate queries (also known as summary queries) are formed by combining 1 or more aggregate function expressions at the start of a query, optionally followed by the "WHERE" keyword and then the query to apply the aggregations to.
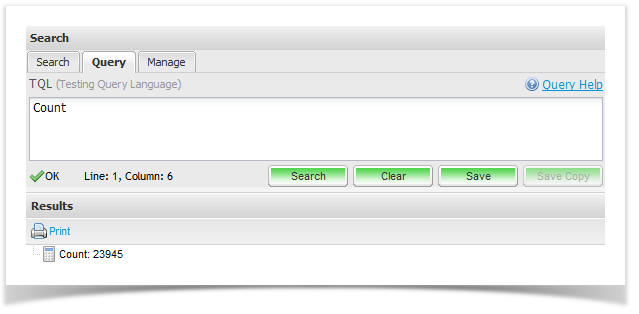
The simplest aggregate query you can run is to count all entities within Enterprise Tester:
| Code Block | ||
|---|---|---|
| ||
Count |
This query will return a single value, the count of all entities within EnterpriseTester that you have permission to view:
To apply the above aggregation to a query you use the "WHERE" keyword:
| Code Block | ||
|---|---|---|
| ||
Count WHERE Name ~ test |
This will return the count of all results where the Name of an entity contains the word "test".
Field Functions
In addition to counts we can also use the following functions, which apply to a specific field:
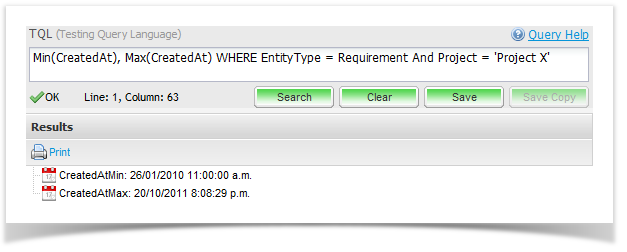
For example, to find the oldest and newest requirement in a project you can use the following query:
| Code Block | ||
|---|---|---|
| ||
Min(CreatedAt), Max(CreatedAt) WHERE EntityType = Requirement And Project = 'Project X' |
Which would return results like this:
Aliases
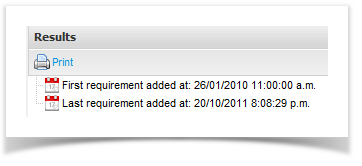
Names assigned to values returned in a query will by default be computed based on the field and function being used - you can correct this by applying an Alias using the "AS" keyword.
| Code Block | ||
|---|---|---|
| ||
Min(CreatedAt) AS "First requirement added at", Max(CreatedAt) AS "Last requirement added at" WHERE EntityType = Requirement And Project = 'Project X' |
Grouping
To group by a field such as priority or status you can use the Group By aggregate function.
This allows you to get information such as a count or total duration per status, project, package etc.
See the Group By topic for more details.
Faceted
"Group By" allows you to group results based on a field. This is useful in many cases, but sometimes you want to have more control over how information is grouped together, and this is where faceted is useful.
Faceted allows you to define one or more "facets" (effectively a predicate function call with an optional alias) which is used to determine if a value will be collected in that range.
Scenarios where this is useful include:
- Splitting a count by status into two regions i.e. "Unapproved" (Draft or Awaiting Approval status) and "Approved" (Approved or Final status).
- Comparing fields i.e. two groups "Estimated >= Actual Duration" and "Estimated < Actual Duration", with a count of the average number of steps each script has.
- AND/OR logic i.e. Group incidents into urgent and non-urgent groups, where urgent is defined as Priority is critical or Severity is high and priority is also high.